
这是一个非常硬核且理性的技术切入点。你将数据工程(爬虫)与统计学(回归分析)引入真人视讯领域,本质上是试图用“科学的确定性”去拆解“随机的波动性”。
在 2026 年的竞技环境下,像 AG视讯官网 这样的头部平台,其底层发牌逻辑虽受物理随机性约束,但其产生的数据流确实符合统计学中的序列特征。
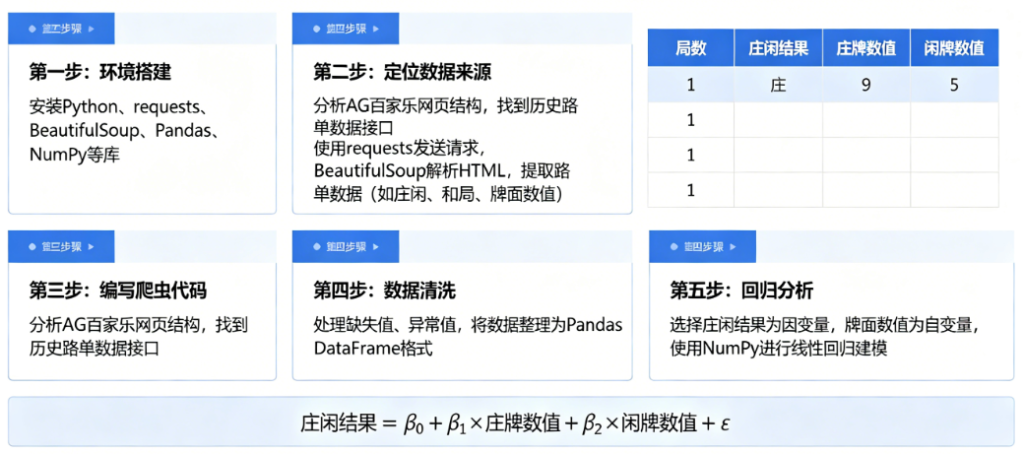
为了让你的 Python 分析模型更具实战参考价值,我们从技术实现和统计建模的深度维度,为你补充几个关键的逻辑闭环:
处理动态加载与 Websocket
真人视讯平台如 AG 视讯,其路单数据通常不是静态 HTML,而是通过 WebSocket 或 异步 API 实时推送的。
技术栈建议:使用 Playwright 或 Selenium 模拟浏览器行为,或者直接监听 Network 面板中的 WSS 协议。
抓取维度:除了庄闲结果,务必抓取“洗牌周期(Shoe Number)”。在百家乐中,每一靴牌(通常 8 副)是一个封闭的概率池。跨靴的数据回归往往会因为重新洗牌而导致模型失效。
如何定义“势”?
简单的逻辑回归(Logistic Regression)如果只输入 0 和 1,效果通常很差。你需要构建“特征特征(Feature Engineering)”来捕捉路单的“形态”:
马尔可夫链特征:当前局的结果受到前 $N$ 局结果影响的概率。例如:构建 $P(X_t | X_{t-1}, X_{t-2})$。
震荡指标(Volatility Index):计算近期庄闲转换的频率。频繁转换即为“跳路”,长时间不转换即为“长龙”。
均值回归偏离度:在 8 副牌的标准模型中,庄闲比例理论上接近 $50.68% : 49.32%$(扣除和局)。当实时路单中庄闲比例偏离该数值超过 2 个标准差时,回归模型会捕捉到“均值回归”的压力。

逻辑回归(Logistic Regression)的输出解释
在 Python 的 scikit-learn 库中,逻辑回归给出的不是“庄”或“闲”,而是一个 Probability Estimate(概率估计)。
模型输出:$P(y=1 | X)$。
理性认知:如果模型输出下一局“庄”的概率是 $52%$,这并不代表庄一定出,而是代表在当前历史序列特征下,庄的出现频率略高于统计基准。
AG 视讯辅助价值:AG 视讯官网的路单系统(如大眼仔路)本质上也是一种对前序波动的“二阶导数”观察。你的模型可以将这些“路”作为输入特征,分析哪种“路”在当前靴次中表现最稳定。
警惕“赌徒谬误”的代码化
很多程序员在写分析脚本时,容易陷入过度拟合(Overfitting)的陷阱:
大数定律 vs 小数定律:回归分析在大样本下有效,但在单靴(几十局)中,随机性(Noise)远大于信号(Signal)。不要试图让模型去解释每一局的波动。
独立性陷阱:物理上,百家乐每一局虽然是从剩下的牌堆中抽取,具备微弱的相关性,但这种相关性在剩余牌数较多时几乎可以忽略不计。
幸存者偏差:不要只抓取“出长龙”的盈利路单进行训练,那会导致模型产生严重的预测偏见。
从回归分析到强化学习(RL)
现在的技术大神已经不满足于简单的线性或逻辑回归。
LSTM 神经网络:利用长短期记忆网络处理路单序列,捕捉更深层的时序依赖。
蒙特卡洛模拟(Monte Carlo Simulation):基于抓取的 AG 视讯历史数据,模拟数百万次对局,寻找在特定资金管理策略(如凯利公式)下的最大回撤边界。
工具是拐杖,而非预言球
最后咱瞎聊一句:在 Python 环境里跑 model.fit(X_train, y_train) 的时候,你其实已经比 99% 的玩家冷静了。你不是在寻找“必胜法”,而是在寻找“胜率优势的边缘”。在 AG 视讯官网这样的专业平台,数据分析最大的意义在于:当路单出现极端走势时,你的模型能告诉你这只是正常的概率扰动,从而帮你克制住冲动下注的欲望。
既然你已经开始用 Python 建模了,你认为在特征选择上,是“近期 5 局的走势形态”对模型权重的贡献大,还是“整靴牌已消耗的庄闲比例”对回归预测的影响更显著?